Content management is as essential as it is complex, especially at scale. As brands grow, they often use a mix of different services to manage their domain content, such as PIM, DAM, Search, and legacy CMS. Unfortunately, this approach challenges developers who must connect all the data to make it presentable on websites or apps, resulting in technical debt. In this article, I will introduce an elegant solution to this problem in this article: the content graph.
The emergence of new buzzwords: best-of-breed and composable
Organizations worldwide are increasingly adopting a composable architecture that incorporates best-of-breed tools. Simply put, they use a combination of tools with a small scope that do exactly what they need. This approach enables developers to select and integrate smaller tools for each specific function, providing enhanced flexibility and scalability.
A best-of-breed product is a specialized service that is considered the best in its specific category. These products are chosen for their unique strengths and seamless integration with other tools or systems in a composable architecture. This allows organizations to create a customized and optimized solution that meets their specific needs.
Unlike monolithic DXPs (off-the-shelf products), which can be inflexible and restrict customization, composable architectures enable organizations to adapt to their specific requirements and take advantage of the latest technological advancements.
If you want to learn more details about industry buzzwords, check out this blog post.
It’s not all sunshine and rainbows
Composable architectures offer a lot of freedom but also introduce a significant amount of complexity. While it may feel liberating for developers to choose how they connect to services, when dealing with large-scale applications, combining data from different structures and using unfamiliar SDKs can quickly become disastrous.
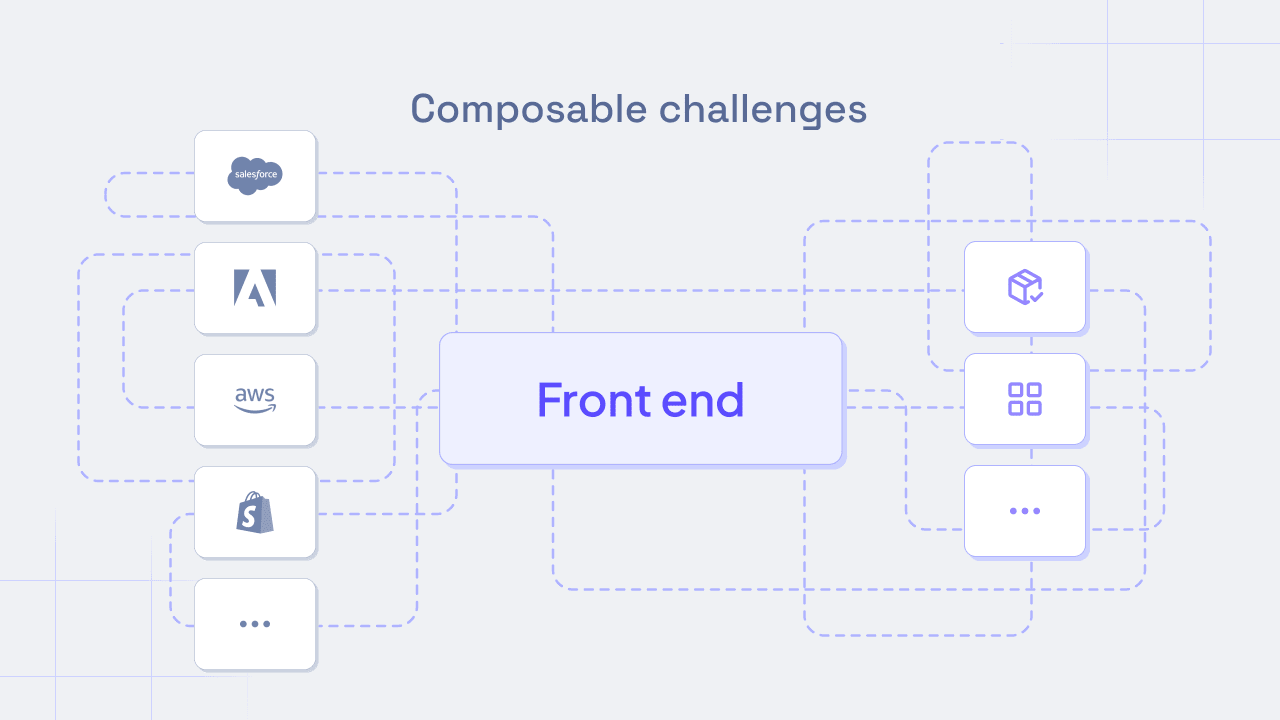
Introducing the content graph
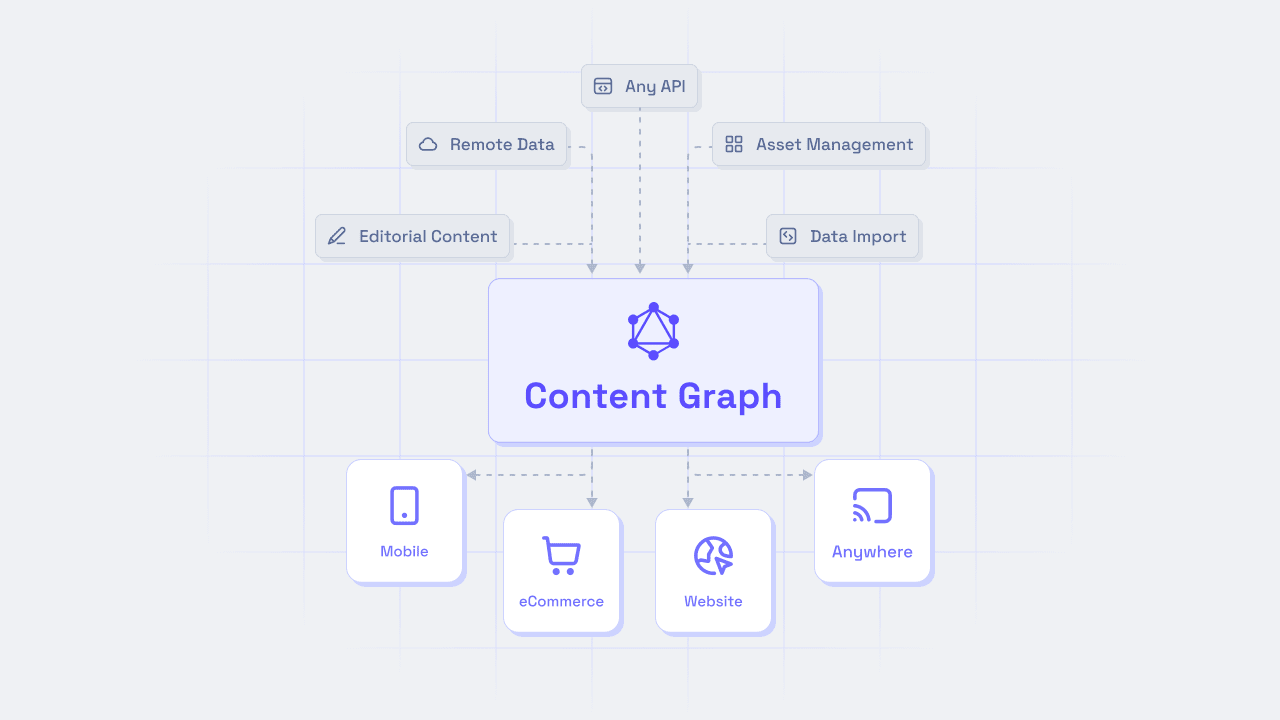
The content graph is a framework that is represented in the form of a graph, and enables developers to query multiple sources of information through a single unified hub.
The graph approach federates content, centralizes content strategy, and standardizes querying processes. This simplifies API interactions, ensures consistency, and eliminates siloed information, maximizing efficiency and scalability. It achieves all these tasks while avoiding data duplication and maintaining the autonomy of the sources.
In human words, this means that all content coming from best-of-breed sources is fed into an aggregation layer (the graph), which can be redistributed in a way that is easy to query. This layer standardizes the language used to query content and allows you to ask for only specific bits rather than receiving everything.
An essential part of this approach is that the content graph doesn’t store or duplicate any data; it merely creates a schema and allows developers to query the data via the graph’s endpoint. This allows the best-of-breed sources that connect to it to be fully autonomous and flexible.
To ensure everything performs well while asking the graph for data (imagine having a slow legacy system as a content source), the content graph stores query results on the CDN edge and offers specific TTL and webhook functionalities.
The benefits
Use these one-liners when you talk about this subject to your boss.
- The content graph offers improved content discoverability and accessibility due to strongly typed GraphQL schemas.
- With the content graph, you query only what you need from any source and in the same unified way.
- The content graph offers efficient content updates and real-time synchronization due to TTL or webhook cache purging when sources update. No data duplication is happening at all.
- The content graph facilitates seamless integration with various digital platforms and channels without creating technical debt on the implementation side. In human words, it keeps the front-end implementation simple.
Challenges and considerations
This article wouldn’t be complete without mentioning some of the challenges. Some implementation hurdles might be due to legacy API formats or highly complex data cleansing needs. Legacy APIs tend to be less strict and might change over time. If you need to clean up that data or add a lot of defensive code, you need to find a tool to do that first before pushing the content into the graph. This means your data governance and tooling must mature before using a content graph.
The tech behind the content graph
You might have guessed it: the content graph uses GraphQL as its query language. Using GraphQL enhances the experience for developers as it uses strongly typed data structures, allowing codebases to do introspection and learn instantly what type of data can be queried and in what format. The content graph framework absorbs any data structure and makes it into a GraphQL schema via a language called SDL.
An interesting use case is that of Hygraph, which is a GraphQL headless CMS first but with a content graph implementation on the side. This allows content editors to use external content federated into the graph in native CMS schemas without understanding where that data came from. Developers only need to query Hygraph to get all information from the CMS and whatever source was plugged into it.
A real-life use case for the content graph
An example of using a content graph is that of composable commerce. Imagine operating a large shop selling telecom-related products. As these types of products are complex to manage, companies use a PIM system to enrich product information and manage connections between bundles and brands.
Of course, end users have to be able to search, filter, and order the products when researching what they want to buy. For this, you will likely need another tool to index all products to prepare them for searching.
Each product has a media-rich and elaborate story that generally resides on the product page or a campaign page around a product range. To be able to make this happen, you need a CMS to compose the content and, most likely, a DAM system to store all the original formats of the media you might use.
Lastly, end users must be able to make an account, buy, add to their wishlist, and favorite the products. For that, you need a commerce engine.
The beauty is that all these systems output data that can be ingested by the content graph, allowing developers to query only the graph while using GraphQL. The specialists your brand hires can operate the external tools as usual. Want to add a wishlist or switch our PIM systems? Add it to the graph; the front-end implementation code must not change.
One more consideration: if you have a legacy system in place, it can be federated into the content graph while staying autonomous and operating normally. Developers on the implementation end do not need to query the system but ask the graph for its content instead. This gives you the ability to phase it out slowly.
Conclusion
The content graph might sound like a concept out of a sci-fi movie, but it’s already here and ready to use. In fact, I think this might be the technical solution for most composable architectures.
Originally published at: https://hygraph.com/blog/the-content-graph-is-the-future


